
Unit 01 Data Science Project #
The final project for this unit will be a research project. Working with the data science tools we explored this unit, you are expected to tell a narrative story about a time in your life using data as evidence.
To be successful in this project, you should find a topic that is both interesting to you and answerable (at least in part) with data from your chosen dataset. Your teachers will help you make sure your project hypothesis achieves that.
[1] Timeline #
1️⃣ Plan your project and choose a research question.
2️⃣ Conduct the data analysis and create data visualizations.
3️⃣ Create a research poster to communicate your findings.
4️⃣ Present your findings to the class.
5️⃣ If interested, you may present your findings at Shuyuan Research Week in June. This is not required.
[2] Starter Materials #
💻 You can find your project in your Google Drive: Project: Data Science.ipynb
✏️ For the poster, you may use Canva or any other service. It will be A3 size. You will begin the poster after you finish the coding portion.
[3] Assessment #
✅ The assessment is broken down into four criteria:
- Project Planning
- Data Analysis
- Data Visualization
- Data Communication
For each criteria you will be assigned a score from 0-3:
- 0 - no to no evidence of the concept
- 1 - limited evidence of the concept
- 2 - adequate evidence of the concept
- 3 - substantial evidence of the concept
[4] Success Claims #
💯 Successful computer scientists should be able to make the following claims:
- Project Planning
- I can choose a relevant research question and determine appropriate forms of evidence
- I can write out the necessary steps for each form of evidence
- I can sketch an appropriate visualization for each form of evidence
- Data Analysis
- I can prepare my dataset by adding and removing necessary columns or rows
- I can combine and reorganize pieces of data to explore new relationships and support my research question
- I can generate summary statistics (mean, median, mode, or frequency count) for describing the data
- I can write readable code by using descriptive names for modules, functions, and variables
- I can write descriptive comments to describe complex pieces of the code
- Data Visualization
- I can choose appropriate data visualizations to communicate my findings
- I can write accurate title, axis, and labels for my visualizations
- I can display data visualizations that are thoughtfully sorted and easy to read
- Data Communication: Poster
- I can describe the dataset
- I can explain the purpose and focus of the research question
- I can reflect on the meaning of the data and provide context for each form of evidence
- I can consider potential future areas of investigation if I were to continue this project
Keep the success claims in mind when coding your project.
[5] Tips & Tricks #
Detecting Chinese Characters #
Here is an example of how to detect if there are Chinese characters in a string.
- You will need to import
regex - Then use
regex.search()- it will return eitherTrueorFalseif there are Chinese characters
import regex
chinese_string = "上海 2025"
if regex.search(r'\p{Han}', chinese_string) == True:
print("Has Chinese!")
else:
print("No chinese")
Detecting Chinese Characters #
import re
text = "hello world 💀 🌈"
# loop through each character
for char in text:
# if you find a character, immediately say you have an emoji
if char in re.findall(u'[\U0001f300-\U0001f650]', char):
print("found an emoji!")
print("end of string")
Find the mode of a column for each unique value in another column #
📖 Here is a dataframe stored in the variable age_df. It stores names, ages, is_adult, and house.
age_df.head()
| name | age | is_adult | house | |
|---|---|---|---|---|
| 0 | Alice | 10 | False | fire |
| 1 | Bob | 15 | False | metal |
| 2 | Charlie | 25 | True | metal |
| 3 | David | 40 | True | fire |
| 4 | Sally | 80 | True | fire |
📖 We want to see what is the mode of is_adult for each house. For this we must use groupby.
mode_isAdult_by_house_df = age_df.groupby(['house'])['is_adult'].agg(pd.Series.mode).to_frame().reset_index()
📖 Here is the new dataframe mode_isAdult_by_house_df.
For
metal, becauseTrueandFalseappear the same amount of times it returns both options.
mode_isAdult_by_house_df
| house | is_adult | |
|---|---|---|
| 0 | fire | True |
| 1 | metal | [‘False’,‘True’] |
This tutorial is based of this post.
Find the mean of a column for each unique value in another column #
📖 Here is a dataframe stored in the variable age_df. It stores names, ages, is_adult, and house.
age_df.head()
| name | age | is_adult | house | |
|---|---|---|---|---|
| 0 | Alice | 10 | False | fire |
| 1 | Bob | 15 | False | metal |
| 2 | Charlie | 25 | True | metal |
| 3 | David | 40 | True | fire |
| 4 | Sally | 80 | True | fire |
📖 We want to see what is the mean age for each value in is_adult. For this we must use groupby.
You could also replace
.mean()with.max()or.min()To round the mean, add
.round(3)after.mean()
mean_isAdult_by_age_df = df.groupby(['is_adult'])['age'].mean().to_frame().reset_index()
📖 Here is the new dataframe mean_isAdult_by_age_df.
mean_isAdult_by_age_df
| is_adult | age | |
|---|---|---|
| 0 | True | 50.5 |
| 1 | False | 12.5 |
Compare a value to the value right above it #
This is particularly useful to learn if you listened/watched the same piece of media multiple times in a row.
📖 Here is a dataframe stored in the variable watch_history_df. It stores shows, episodes, and genre.
df.head()
| food | |
|---|---|
| 0 | Siu Mai |
| 1 | Siu Mai |
| 2 | Ice Cream |
| 3 | Kinder Bueno |
| 4 | Kinder Bueno |
| 5 | Kinder Bueno |
📖 We want to add a column to see what the previous item was called. For this we must use shift.
You could also put a number in the brackets to shift more than just 1 row down
For example,
.shift(2)or.shift(-1)
df['previous'] = watch_history_df['show'].shift()
df.head()
| food | previous | |
|---|---|---|
| 0 | Siu Mai | None |
| 1 | Siu Mai | Siu Mai |
| 2 | Ice Cream | Siu Mai |
| 3 | Kinder Bueno | Ice Cream |
| 4 | Kinder Bueno | Kinder Bueno |
| 5 | Kinder Bueno | Kinder Bueno |
📖 Now we will add a new column to track if the show is the same as the previous one.
df["repeat"] = df["show"] == df["previous"]
df.head()
| food | previous | repeat | |
|---|---|---|---|
| 0 | Siu Mai | None | False |
| 1 | Siu Mai | Siu Mai | True |
| 2 | Ice Cream | Siu Mai | False |
| 3 | Kinder Bueno | Ice Cream | False |
| 4 | Kinder Bueno | Kinder Bueno | True |
| 5 | Kinder Bueno | Kinder Bueno | True |
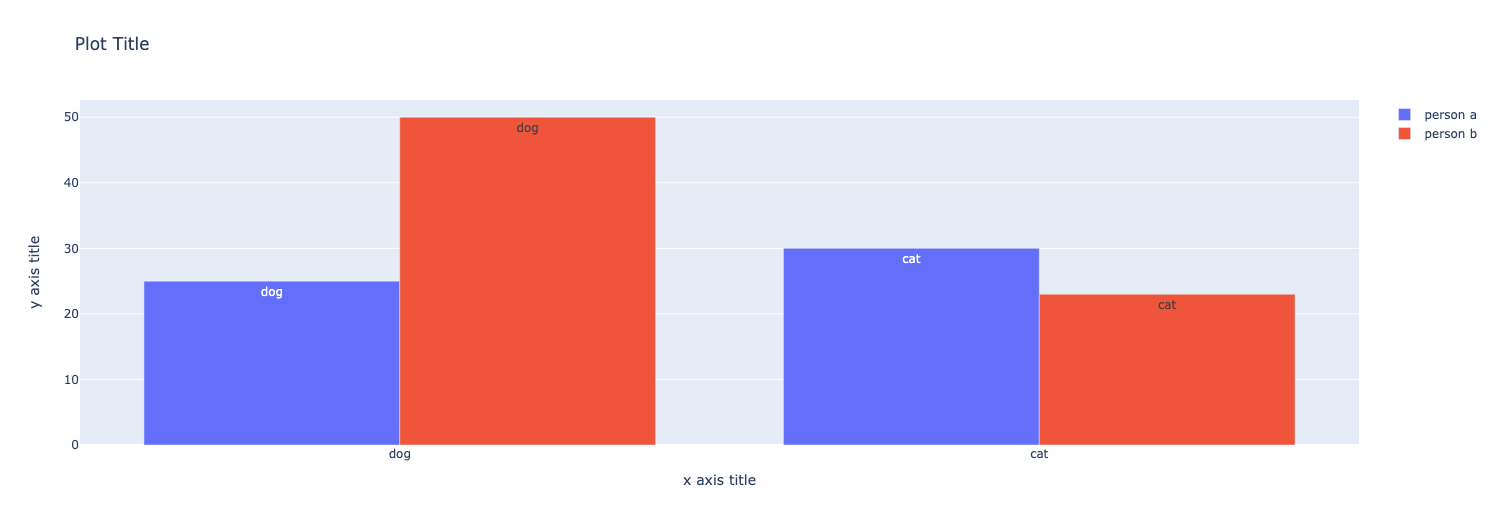
Grouped Bar Chart #
A grouped bar chart allows you to compare multiple sets of similar data.
📖 In this chart, we compare two people and their number of cats and dogs. Their data is stored in person1df and person2df. The dataframes are identical, except for the count column.
person1df
| animal | count | |
|---|---|---|
| 0 | dog | 25 |
| 1 | cat | 30 |
person2df
| animal | count | |
|---|---|---|
| 0 | dog | 50 |
| 1 | cat | 23 |
📖 This is how you create a group bar chart with two dataframes.
fig = go.Figure(data=[
go.Bar(name='person a', x=person1df.animal, y=person1df.count, text=df1.Name),
go.Bar(name='person b', x=person2df.animal, y=person2df.count, text=df2.Name)
])
fig.update_layout(
barmode='group',
title="Plot Title",
xaxis_title="x axis title",
yaxis_title="y axis title",
)
fig.show()
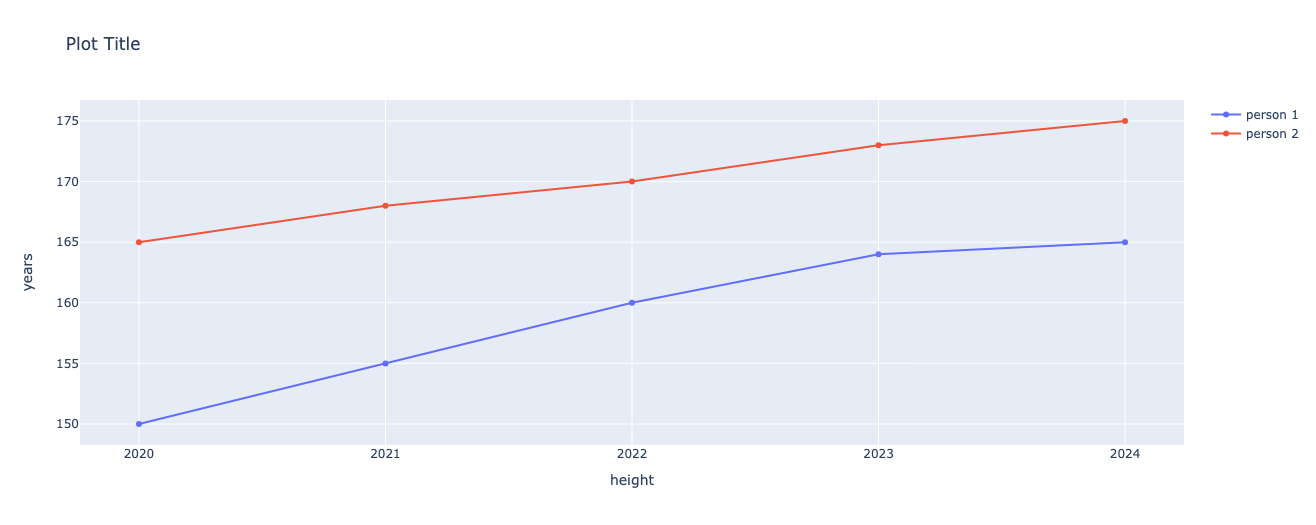
Line Charts with Many Lines #
A grouped bar chart allows you to compare multiple sets of similar data.
📖 In this chart, we compare two people and their heights over 5 years. Their data is stored in person1df and person2df. The dataframes are identical, except for the count column.
person1df
| year | height | |
|---|---|---|
| 0 | 2020 | 150 |
| 1 | 2021 | 155 |
| 2 | 2022 | 160 |
| 3 | 2023 | 164 |
| 4 | 2024 | 165 |
person2df
| year | height | |
|---|---|---|
| 0 | 2020 | 165 |
| 1 | 2021 | 168 |
| 2 | 2022 | 170 |
| 3 | 2023 | 173 |
| 4 | 2024 | 175 |
📖 This is how you create a group bar chart with two dataframes.
fig = go.Figure()
fig.add_trace(go.Scatter(x=person1df.year, y=person1df.height, name='person 1'))
fig.add_trace(go.Scatter(x=person2df.year, y=person2df.height, name='person 2'))
fig.update_xaxes(type='category') # only exisiting values for ticks
fig.update_layout(
title="Plot Title",
xaxis_title="height",
yaxis_title="years",
)
fig.show()
Adding Other #
This can be helpful if you’d like to show your top 5 in relationship to the other items in a dataset.
1️⃣ Make a new dataframe with just the top 5 artists For this we must use head.
top3_df = df.head(3)
| food | num_purchased | |
|---|---|---|
| 0 | Siu Mai | 20 |
| 2 | Kinder Bueno | 15 |
| 3 | Ice Cream | 10 |
2️⃣ Make a new dataframe with all data except the top 3 items. We use iloc to select specific rows.
other_df = df.iloc[3:]
3️⃣ We add up the totals for all the other items. To do this, we use sum.
other_sum = other_df["num_purchased"].sum()
4️⃣ We add a new row for the other sum and add it to the top3_df.
# create the new row
new_row = {'food': 'Other', 'num_purchased': other_sum}
# make a new df that combines the top5_df with the new row
combo_df = top3_df.append(new_row, ignore_index = True)
📖 Here is the new dataframe combo_df.
| food | num_purchased | |
|---|---|---|
| 0 | Siu Mai | 20 |
| 2 | Kinder Bueno | 15 |
| 3 | Ice Cream | 10 |
| 4 | Other | 8 |
Drop Duplicate Values #
This may be helpful with the Youtube dataset if you are interested in analyzing what type of channels you watch.
df.head()
| name | age | |
|---|---|---|
| 0 | John | 20 |
| 1 | Paul | 23 |
| 2 | Ringo | 18 |
| 3 | Ringo | 18 |
no_duplicates_df = df.drop_duplicates()
no_duplicates_df.head()
| name | age | |
|---|---|---|
| 0 | John | 20 |
| 1 | Paul | 23 |
| 2 | Ringo | 28 |